
Deep Dive Into AWS Lambda – Part III
The third and last part of this mini-series discusses concurrency, an important concept in applications backed by AWS Lambda. You will learn about what concurrency is and what modifications you can make to your Lambda function. Furthermore, we will take a short look at the monitoring of Lambda functions. As usual, we recommend reading the Introduction into Lambda and the first two parts of the deep dive.
Concurrency
Concurrency is an important topic in AWS Lambda. This section introduces the basic idea, why AWS enforces a concurrency limit, and when to reserve or provision concurrency.
Concurrency means serving a certain number of requests at the same time with a Lambda function. When a function is invoked, an instance (not an EC2 instance!) of that function is created to serve the request. Think of a class and instances of a class. If the function is not done running at the time another request needs to be served, another instance is allocated. This increases the concurrency level which is limited per region and account. As of this writing, the concurrency limit within a region equals 1000 executions per account. If you need a higher limit, you can ask the support center for a service limit increase. The limit protects users from unexpected costs that occur due to recursive code or other unintended invocations.
You can configure reserved concurrency to ensure, that a function is not throttled until it reaches a certain concurrency level. When you reserve concurrency you should analyze the needed capacity carefully. Otherwise, you might reserve too much concurrency which will result in other functions within the region being throttled.
The following figure visualizes the principle of reserved concurrency. The two functions, my-function-DEV/PROD, consume reserved concurrency which leaves the remaining concurrency of the region for other functions. Important to notice: The DEV-function hits the limit of the reserved concurrency and is throttled.
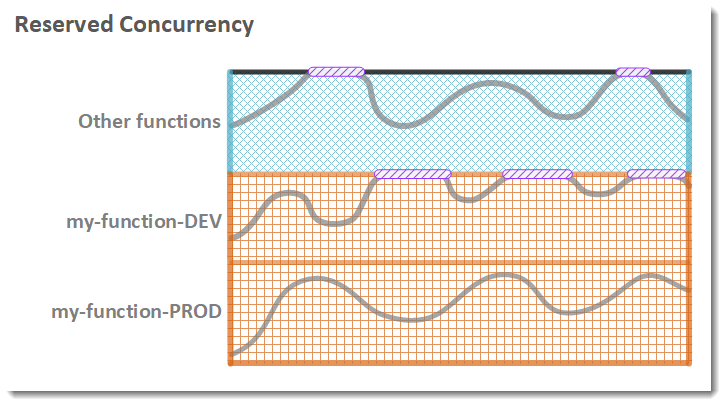
 Function concurrency
Function concurrency- Reserved concurrency
- Unreserved concurrency
- Throttling
 Function concurrency
Function concurrency Reserved concurrency
Reserved concurrency Unreserved concurrency
Unreserved concurrency Throttling
ThrottlingReserving concurrency is useful when you work with workloads that underly foreseeable peaks or you want to ensure, that a specific function is never throttled. Alternatively, you can implement exponential back in the application that invokes the Lambda function.
To avoid latency fluctuations when scaling out Lambda functions you can use provisioned concurrency. Latency fluctuations happen every time your function is invoked as a cold start. Each new instance of the function equals a cold start. The runtime loads every dependency. Depending on the size this might takes time. Hence, every new instance needs a certain amount of time to become available. Consequently, a “running” instance (warm start) serves requests faster than new instances. Provisioned concurrency ensures that requests use “warm” function instances if possible.
Burst management also benefits from provisioned concurrency as well. Provisioned concurrency scales a function stepwise in case the functions hits its limit. The concurrency limit is increased by 500 per minute until the request is fulfilled.
Monitoring
Monitoring is a built-in feature of AWS Lambda. When creating a new function, you should make sure, that the function’s permissions allow for writing logs to CloudWatch. The following permissions need to be granted:
logs:createLogStreamlogs:PutLogEventslogs:CreateLogGroup
Alternatively, AWS Lambda can create a new role for you upon the creation of the function. In that case, Lambda adds the needed permissions automatically to the IAM role. The function needs these permissions because it creates a log group on your behalf and sends logging data into the log group for additional analysis or debugging.
Additionally, every function has a dedicated monitoring console that can be reached in the context menu of the function. The console provides the following graphs:
- Invocations – The number of times that the function was invoked aggregated in a 5-minute period.
- Duration –The average, minimum, and maximum execution times.
- Error count and success rate (%) – The number of errors and the percentage of executions that completed without error.
- Throttles – The number of times that execution failed due to concurrency limits.
- IteratorAge – For stream event sources, the age of the last item in the batch when Lambda received it and invoked the function.
- Async delivery failures – The number of errors that occurred when Lambda attempted to write to a destination or dead-letter queue.
- Concurrent executions – The number of function instances that are processing events.
- Concurrency can be monitored in AWS CloudWatch. It shows you the number of concurrent executions in your account per region.
Even more information can be analyzed in CloudWatch. Every time the function finished, it sends its data to CloudWatch. You can either examine logs of the function which show the start and end of a request as well as all logging statements that were made throughout processing.
Alternatively, you can build custom dashboards. Each element in the dashboard visualizes data in one of the following categories:
- Function: Metrics for a specific function
- By resource: Metrics for a certain version or alias
- Across all functions
For more information on metrics and monitoring of Lambda functions, take a look at the developer documentation [2].
This was the last article dedicated to AWS Lambda. We hope you enjoyed learning about this extremely useful service and are already off to build awesome applications backed by AWS Lambda. If you have any feedback on the series or questions regarding AWS Lambda, do not hesitate and reach out to us!
[1] https://docs.aws.amazon.com/lambda/latest/dg/configuration-concurrency.html
[2] https://docs.aws.amazon.com/lambda/latest/dg/monitoring-metrics.html
More information on the topic: