
Apache Airflow and AWS: A powerful combination for data pipelines
Apache Airflow is a powerful tool in the world of data processing. Airflow shines in the orchestration of complex workflows.
The following blog article provides a compact overview of Apache Airflow and a project report from one of our customers.
This is Airflow
Airflow is a cross-platform framework for the programmatic creation, planning and monitoring of workflows. It enables the definition of workflows as Directed Acyclic Graphs (DAGs), in which individual tasks are linked together. These tasks can include any number of processes, from simple scripts to complex ETL processes.
Advantages of Airflow
- Flexibility: Airflow offers a high degree of flexibility when defining workflows.
- Scalability: By using different executors, Airflow can be adapted to growing requirements.
- Visual representation: The graphical representation of DAGs facilitates understanding and troubleshooting.
- Community: A large and active community supports the development and provision of new features.
AWS offers managed services for Airflow with Amazon Managed Workflows for Apache Airflow (MWAA). These services significantly simplify the deployment, management and scaling of the platforms.
Use cases for Apache Airflow
Apache Airflow is used in many scenarios to orchestrate complex data processing and automation tasks. Here are some application examples:
- Coordination of batch ETL jobs (extract, transform, load)
- Arrangement, execution and tracking of data workflows
- Managing data pipelines that evolve slowly (over days or weeks instead of hours or minutes), are tied to specific time periods or are scheduled in advance
- Create ETL pipelines to retrieve batch data from various sources and run Spark jobs or other forms of data processing
- Train machine learning models, e.g. by triggering a SageMaker job
- Creating reports automatically
- Performing backups and other DevOps tasks, such as running a Spark job and saving the output to a Hadoop cluster
Project report
The client
The customer is a company from the financial sector with around 5,000 employees that processes and analyzes large volumes of data from various sources to support business decisions.
The challenge
The client faces the challenge of implementing effective ETL (Extract, Transform, Load) processes to efficiently process and prepare data for analysis. The specific challenges in this context are:
Data extraction: The regular retrieval of data from different sources such as databases, APIs or files represents a significant challenge. It must be ensured that the data is retrieved completely, up-to-date and consistently in order to create a reliable basis for further processing steps.
Data cleansing and transformation: After extraction, the raw data must be converted into a format that is suitable for analysis. This includes the cleansing of incomplete or incorrect data and the standardization of different data formats. This step is often complex and requires special rules and methods to transform the data correctly.
Data loading: Finally, another challenge is to load the transformed data into an RDS (Relational Database Service), which acts as a data warehouse or data mart. This requires careful planning in order to store the data efficiently and optimize access for analysis purposes.
The solution
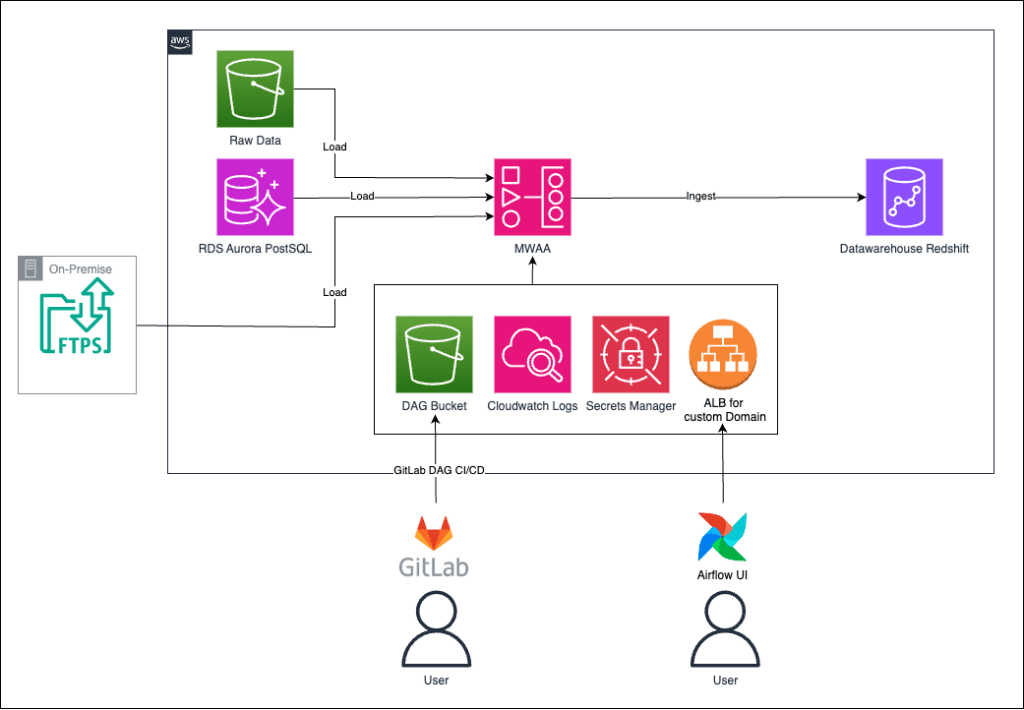
Data stored in S3 buckets, Aurora databases and FTPS shares should be processed at regular intervals. The administration and orchestration of the data processing processes takes place in the MWAA environment (managed airflow environment). Finally, the data is stored in a data warehouse, which is the destination of the data transport. The PostgreSQL database in which the transformed data is stored is located within the data warehouse.
The DAGs (Directed Acyclic Graphs), which are responsible for controlling the data processing, are loaded into the S3 bucket via GitLab. CloudWatch monitors the entire process and provides log data to track the status and any errors. The access data and passwords required to access the various data sources and destinations are stored in encrypted form in the AWS Secret Manager. It is possible to access the Airflow UI and manage the environment via an Application Load Balancer (ALB).
How it works
The data processing process is triggered daily by the Airflow DAG. First, the extract_data function is executed, which loads the data from the various sources (S3 bucket, Aurora, FTPS). The transform_data function then prepares the raw data, for example by removing headers or converting data types. Finally, the load_data function loads the transformed data into the data warehouse, where it is stored in the PostgreSQL database.
The advantages
The solution offers the customer several advantages through the use of various AWS services:
- Automation: the MWAA environment automates recurring ETL processes (extraction, transformation, loading).
- Scalability: Airflow can be easily scaled so that no manual adjustments are required as data volumes increase.
- Low maintenance: Since MWAA, CloudWatch, S3 and Secret Manager are managed, maintenance and administration efforts are eliminated, allowing the focus to be placed on core processes.
- Monitoring: CloudWatch enables detailed monitoring to detect anomalies at an early stage and improve the reliability of the system.
- Integration: The architecture supports various data sources (S3 Bucket, Aurora, FTPS), which enables flexible and efficient data processing.
- Modularity: The architecture is modular so that it can be easily extended with new functions or data sources.
Overall, the architecture provides a cost-effective, secure and flexible solution that simplifies and automates the data processing process while ensuring reliable monitoring and troubleshooting.