
Apache Airflow und AWS: Eine leistungsstarke Kombination für Datenpipelines
Apache Airflow ist ein mächtiges Werkzeug in der Welt der Datenverarbeitung. Airflow glänzt vor allem in der Orchestrierung komplexer Workflows.
Der folgende Blogartikel gibt im ersten Teil einen kompakten Überblick über Apache Airflow. Im zweiten Teil finden Sie einen Projektbericht eines unserer Kunden.
Was ist Airflow
Airflow ist ein plattformübergreifendes Framework zur programmatischen Erstellung, Planung und Überwachung von Workflows. Es ermöglicht die Definition von Workflows als Directed Acyclic Graphs (DAGs), in denen einzelne Aufgaben (Tasks) miteinander verknüpft sind. Diese Aufgaben können beliebige Prozesse umfassen, von einfachen Skripten bis hin zu komplexen ETL-Prozessen.
Vorteile von Airflow
- Flexibilität: Airflow bietet eine hohe Flexibilität bei der Definition von Workflows.
- Skalierbarkeit: Durch die Verwendung von verschiedenen Executors kann Airflow an wachsende Anforderungen angepasst werden.
- Visuelle Darstellung: Die grafische Darstellung von DAGs erleichtert das Verständnis und die Fehlersuche.
- Community: Eine große und aktive Community unterstützt die Entwicklung und Bereitstellung von neuen Features.
AWS bietet mit Amazon Managed Workflows for Apache Airflow (MWAA) verwaltete Dienste für Airflow an. Diese Services vereinfachen die Bereitstellung, Verwaltung und Skalierung der Plattformen erheblich.
Anwendungsbeispiele für Apache Airflow
Apache Airflow wird in vielen Szenarien eingesetzt, um komplexe Datenverarbeitungs- und Automatisierungsaufgaben zu orchestrieren. Hier sind einige Anwendungsbeispiele:
- Koordinierung von Batch-ETL-Aufträgen (Extrahieren, Transformieren, Laden)
- Automatisches Arrangieren, Ausführen und Verfolgen von Daten-Workflows
- Verwaltung von Datenpipelines, die sich langsam entwickeln (über Tage oder Wochen statt Stunden oder Minuten), an bestimmte Zeiträume gebunden sind oder im Voraus geplant werden
- Erstellen von ETL-Pipelines zum Abrufen von Batch-Daten aus verschiedenen Quellen und Ausführen von Spark-Aufträgen oder anderen Formen der Datenverarbeitung
- Trainieren von Modellen für maschinelles Lernen, z. B. durch Auslösen eines SageMaker-Jobs
- Automatisches Erstellen von Berichten
- Durchführen von Backups und anderen DevOps-Aufgaben, wie das Ausführen eines Spark-Jobs und Speichern der Ausgabe auf einem Hadoop-Cluster
Projektbericht
Der Kunde
Der Kunde ist ein Unternehmen aus dem Finanzsektor mit ca 5.000 Mitarbeitenden, das große Mengen an Daten aus verschiedenen Quellen verarbeitet und analysiert, um geschäftliche Entscheidungen zu unterstützen.
Die Herausforderung
Der Kunde stand vor der Herausforderung, effektive ETL-Prozesse (Extract, Transform, Load) zu implementieren, um Daten effizient zu verarbeiten und für Analysen aufzubereiten. Die spezifischen Herausforderungen in diesem Kontext waren:
Datenextraktion: Das regelmäßige Abrufen von Daten aus unterschiedlichen Quellen wie Datenbanken, APIs oder Dateien stellte eine wesentliche Herausforderung dar. Hierbei musste sichergestellt werden, dass die Daten vollständig, aktuell und konsistent abgerufen wurden, um eine zuverlässige Grundlage für die weiteren Verarbeitungsschritte zu schaffen.
Datenbereinigung und Transformation: Nach der Extraktion mussten die Rohdaten in ein Format umgewandelt werden, das für Analysen geeignet war. Dies beinhaltete die Bereinigung von unvollständigen oder fehlerhaften Daten und die Vereinheitlichung unterschiedlicher Datenformate. Dieser Schritt war oft komplex und erforderte spezielle Regeln und Methoden, um die Daten korrekt zu transformieren.
Datenladung: Schließlich bestand eine weitere Herausforderung darin, die transformierten Daten in eine RDS (Relational Database Service) zu laden, die als Data Warehouse oder Data Mart fungierte. Dies erforderte eine sorgfältige Planung, um die Daten effizient zu speichern und den Zugriff für Analysezwecke zu optimieren.
Die Lösung
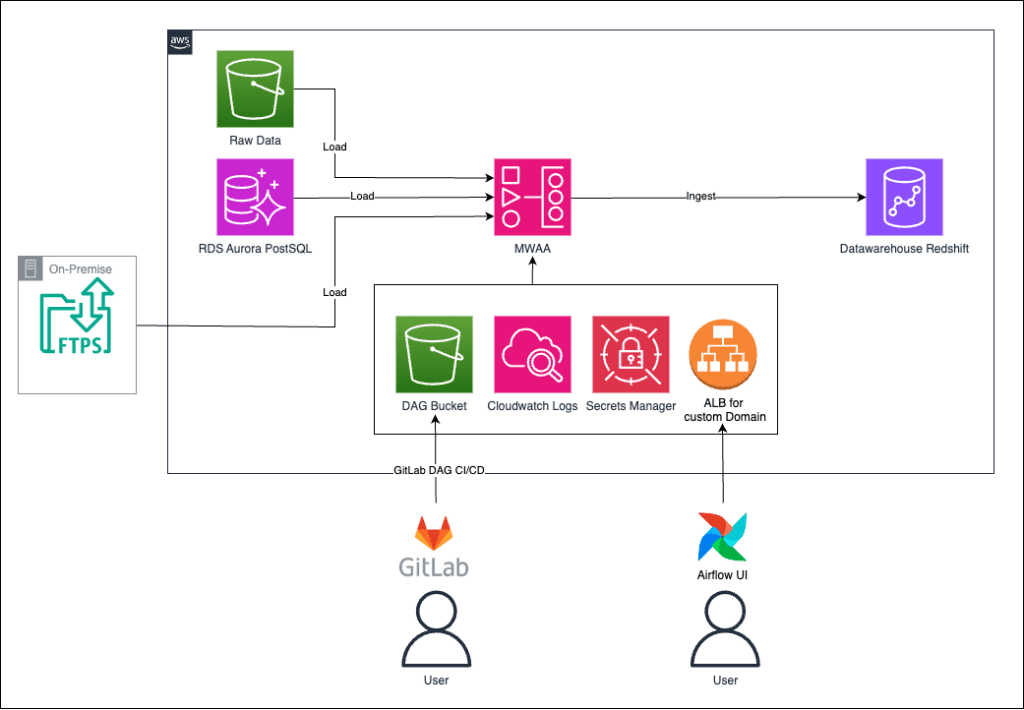
Daten, die in S3 Buckets, in Aurora-Datenbanken und FTPS-Shares gespeichert sind, sollen in regelmäßigen Abständen verarbeitet werden. Die Verwaltung und Orchestrierung der Datenverarbeitungsprozesse erfolgt im MWAA Environment (verwaltete Airflow-Umgebung). Die Daten werden schließlich in einem Data Warehouse, welches das Ziel des Datentransports ist, gespeichert. Innerhalb des Data Warehouses liegt die PostgreSQL-Datenbank, in der die transformierten Daten abgelegt werden.
Die DAGs (Directed Acyclic Graphs), die für die Steuerung der Datenverarbeitung verantwortlich sind, werden über GitLab in den S3 Bucket geladen. CloudWatch überwacht den gesamten Prozess und liefert Logdaten, um den Status und eventuelle Fehler zu verfolgen. Die Zugangsdaten und Passwörter, die für den Zugriff auf die verschiedenen Datenquellen und -ziele benötigt werden, werden im AWS Secret Manager verschlüsselt abgelegt. Über einen Application Load Balancer (ALB) ist es möglich, auf das UI von Airflow zuzugreifen und die Umgebung zu verwalten.
Die Funktionsweise
Der Datenverarbeitungsprozess wird täglich durch den Airflow-DAG ausgelöst. Zuerst wird die extract_data-Funktion ausgeführt, welche die Daten aus den verschiedenen Quellen (S3 Bucket, Aurora, FTPS) lädt. Anschließend bereitet die transform_data-Funktion die Rohdaten auf, indem sie beispielsweise Überschriften entfernt oder Datentypen konvertiert. Abschließend lädt die load_data-Funktion die transformierten Daten in das Data Warehouse, wo sie in der PostgreSQL-Datenbank gespeichert werden.
Die Vorteile
Die Lösung bietet dem Kunden mehrere Vorteile durch die Nutzung verschiedener AWS-Dienste:
- Automatisierung: Das MWAA Environment automatisiert wiederkehrende ETL-Prozesse (Extraktion, Transformation, Laden).
- Skalierbarkeit: Airflow lässt sich einfach skalieren, sodass bei steigenden Datenmengen keine manuelle Anpassung erforderlich ist.
- Wartungsarmut: Da MWAA, CloudWatch, S3 und Secret Manager verwaltet werden, entfallen Wartungs- und Administrationsaufwände, wodurch der Fokus auf Kernprozesse gelegt werden kann.
- Überwachung: CloudWatch ermöglicht eine detaillierte Überwachung, um Anomalien frühzeitig zu erkennen und die Zuverlässigkeit des Systems zu verbessern.
- Integration: Die Architektur unterstützt verschiedene Datenquellen (S3 Bucket, Aurora, FTPS), was eine flexible und effiziente Datenverarbeitung ermöglicht.
- Modularität: Die Architektur ist modular aufgebaut, sodass sie leicht um neue Funktionen oder Datenquellen erweitert werden kann.
Insgesamt bietet die Architektur eine kosteneffiziente, sichere und flexible Lösung, die den Datenverarbeitungsprozess vereinfacht und automatisiert, während zuverlässige Überwachung und Fehlerbehebung gewährleistet sind.