
Deep Dive AWS Lambda – Teil I
In dieser Miniserie möchten wir einen genaueren Blick auf AWS Lambda werfen. Der erste Teil fasst Trigger und Berechtigungen zusammen, welche Ausführungsmodelle berücksichtigt werden müssen und wie der Lebenszyklus einer Lambda-Funktion aussieht. In Einführung in AWS Lambda haben wir bereits die Grundlagen von AWS Lambda besprochen, welche Vorteile sich ergeben und wie mögliche Anwendungsszenarien aussehen könnten.
Trigger und Berechtigungen
AWS Lambda benötigt zur Ausführung zwei wichtige Komponenten: Die sog. „Function Policy“ und eine „IAM Execution Role“. Die Function Policy definiert, welche Services eine Lambda-Funktion aufrufen können. Mögliche Trigger sind Datenspeicher, Endpunkte, Repositories oder Benachrichtigungsdienste.
Die Function Policy wird automatisch erstellt, wenn der erste Trigger zur Funktion hinzugefügt wird. Zusätzlich wird beim Einrichten eines Triggers die Rolle „Lambda:InvokeFunction“ zur Ereignisquelle hinzugefügt. Aber wie sieht eine Richtlinie aus? Die funktionsspezifischen Berechtigungen einer Funktion finden Sie im Hauptmenü der Lambda-Funktion im Tab „Berechtigungen“.
Code-Snippet 1 zeigt eine einfache Function Policy für ein S3-Bucket zum Aufruf von Lambda. Der Hauptschlüssel bezieht sich auf den Dienst, zu welchem die Ressource, in diesem Fall das Bucket, gehört. Außerdem wird die Funktion durch ihre Amazon Resource Number (arn) referenziert, ebenso wie das spezifische Bucket. An dieser Stelle ein wichtiger Hinweis: Die Ressource muss sich in derselben Region befinden wie die Funktion. Die ist erforderlich, obwohl S3 ein globaler Dienst ist. Darüber hinaus müssen Sie beim Hinzufügen neuer Trigger sicherstellen, dass die IAM Execution Role bereits grundlegende Aktionen für den spezifischen Trigger erlaubt.
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "lambda-d33de16c-9e51-4f35-b208-b09ad8d0430a",
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:eu-central-1:***********:function:testFunction",
"Condition": {
"StringEquals": {
"AWS:SourceAccount": "*************"
},
"ArnLike": {
"AWS:SourceArn": "arn:aws:s3:::lambda-test-bucket-f**********"
}
}
}
]
}Die IAM Execution Role definiert, mit welchen Services die Lambda-Funktion agieren darf, sobald sie aufgerufen wird. Die Richtlinie muss bei der Definition einer neuen AWS-Lambda-Funktion ausgewählt oder erstellt werden. In jedem Fall müssen die folgenden drei Berechtigungen für die Funktion erteilt werden:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvens
Diese drei Berechtigungen ermöglichen es Lambda, eine Log-Gruppe in CloudWatch zu erstellen und Informationen an CloudWatch zu senden. Dadurch wird sichergestellt, dass der Benutzer aktuelle Statistiken über die Nutzung, Fehlerzählungen, gleichzeitige Aufrufe und andere Metriken einsehen kann.
Execution Models
Execution Models, zu Deutsch etwa „Ausführungsmodelle“, sind ein weiterer wichtiger Aspekt einer Lambda-Funktion, und müssen beim Entwurf der Architektur einer Anwendung berücksichtigt werden. Unterschieden wird zwischen synchronen/asynchronen Trigger und Polling. Zunächst ein Blick auf synchrone und asynchrone Trigger.
Synchrone Trigger erfordern eine sofortige Aktion der Lambda-Funktion, da der aufrufende Prozess bzw. Service auf Antwort der Funktion wartet. Daher ist es möglich, dass eine fehlerhafte Lambda-Funktion die Anwendung blockiert. Ein weiteres wichtiges Detail ist die Tatsache, dass synchrone Trigger keine automatischen Wiederholungsversuche bieten. Daher muss die Fehlerbehandlung beim Schreiben des Anwendungscodes berücksichtigt werden. Ein Beispiel für einen synchronen Trigger ist das API-Gateway, welches eine Funktion aufruft und dann wartet, bis die Funktion beendet ist, bevor es auf den API-Aufruf eines Benutzers antwortet.
Asynchrone Trigger hingegen erlauben es dem Trigger, die Funktion aufzurufen, ohne auf eine Bestätigung zu warten. Wenn asynchron ausgelöst, versucht die Lambda-Funktion automatisch dreimal ihren Code auszuführen. Zusätzlich können Sie eine Dead Letter Queue (DLQ) konfigurieren, in der die erfolglosen Aufrufe zur weiteren Analyse gespeichert werden. Nach drei fehlgeschlagenen Aufrufen sendet AWS Lambda die entsprechenden Daten automatisch in die DLQ. Die folgende Liste enthält einige mögliche asynchrone Triggerquellen:
- Amazon Simple Storage Service (Amazon S3)
- Amazon Simple Notification Service (Amazon SNS)
- Amazon Simple Email Service (Amazon SES)
- Amazon CloudWatch Logs
- Amazon CloudWatch Events
- AWS CodeCommit
- AWS Config
Wichtig zu wissen: Wird eine Lambda-Funktion programmatisch aufgerufen, muss der Triggertyp angegeben werden. Wenn AWS-Dienste als Quelle verwendet werden, ist der Aufruftyp vorgegeben.
AWS-Lambda-Polling kann eine interessante Alternative zu den besprochenen Ausführungsmodellen sein. Lambda kann verwendet werden, um eine Message Queue oder einen Messagestream abzufragen und ein Nachrichtenobjekt aus der Quelle zu extrahieren. Wichtig zu wissen: Durch die Abfragen entstehen keine Kosten. Erst wenn ein Objekt verarbeitet wird fallen Kosten an. Zudem hängt die Fehlerbehandlung von der Quelle ab. Beim Polling aus einem Stream blockiert ein Fehler die Anwendung, da normalerweise die Reihenfolge der gestreamten Ereignisse von Bedeutung ist. Die Funktion ist so lange blockiert, wie das Ereignis/Objekt gültig ist. Verarbeitungsfehler bei Ereignissen, die aus einer Queue stammen, werden dagegen entweder an eine DLQ gesendet oder verworfen.
Der Lebenszyklus einer Lambda-Funktion
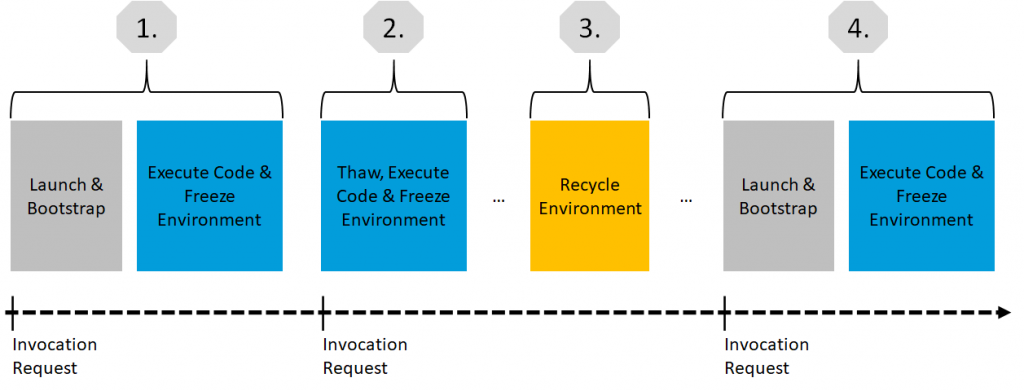
Was passiert, wenn eine AWS-Lambda-Funktion aufgerufen wird? Den Lebenszyklus einer Funktion zu verstehen ist wichtig, wenn man die Preisgestaltung für AWS Lambda verstehen möchte. Die folgenden Schritte werden ausgeführt, wenn eine Funktion aufgerufen wird:
- Beim Aufruf wird eine Ausführungsumgebung (runtime environment) gestartet. Sobald die Umgebung gestartet ist, wird der Funktionscode ausgeführt. Dann friert Lambda die Ausführungsumgebung ein und wartet auf weitere Aufrufe.
- Wenn ein weiterer Aufruf der Funktion angefordert wird, während sich die Umgebung in diesem Zustand befindet, durchläuft diese Anforderung einen sogenannten „Warmstart“. Bei einem Warmstart wird der verfügbare eingefrorene Container aufgetaut und beginnt sofort mit der Codeausführung, ohne den Boot-Prozess zu durchlaufen.
- Dieser Zyklus des Auftauens und Einfrierens dauert so lange an, wie Anfragen weiterhin regelmäßig eingehen. Wenn die Umgebung jedoch zu lange inaktiv ist, wird die Ausführungsumgebung recycelt.
- Bei einer nachfolgenden Anforderung beginnt der Lebenszyklus von vorn, so dass die Umgebung gestartet werden muss. Dies wird als „Kaltstart“ bezeichnet.
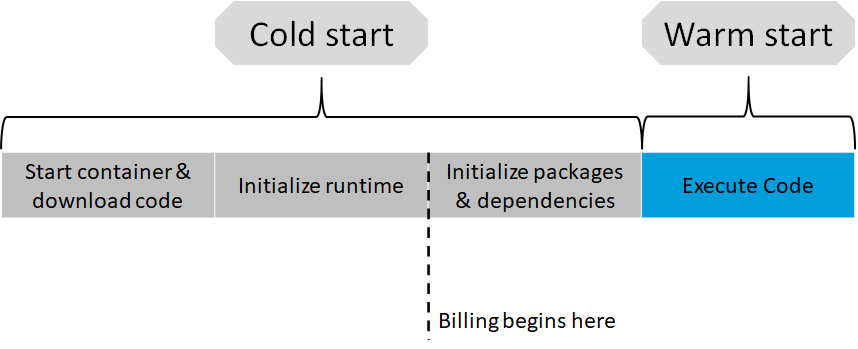
Wie hängt dies mit der Preisgestaltung zusammen? Die kostenpflichtige Laufzeit einer Funktion beginnt, sobald Pakete und Abhängigkeiten initialisiert werden. Von diesem Zeitpunkt an sollte die Ausführungsumgebung so schlank wie möglich gestaltet sein, indem nur die Abhängigkeiten und Pakete importiert werden, welche zur Ausführung des Codes erforderlich sind.
Dies war der erste Teil der Miniserie über AWS Lambda. Im zweiten Teil werfen wir einen Blick auf Best Practices beim Entwerfen und Schreiben von Code für Lambda. Außerdem betrachten wir Concurrency und Limitierungen von AWS Lambda.
Weitere Informationen zum Thema (Eng.):