
Dependencymanagement für AWS Lambda
Jeder Entwickler*in nutzt Bibliotheken, welche Funktionalität bieten und gleichzeitig Entwicklungsaufwand minimieren. Bei der “herkömmlichen” Entwicklung von Software ist das Einbinden zusätzlicher Softwarepakete meist kein Probem (Sicherheitsbedingte Netzwerkeinschränkungen außer acht gelassen). Im Fall von Softwareentwicklung für den Serverless Compute Service Lambda von AWS können hier jedoch Probleme auftreten. Dieser Beitrag beleuchtet das Problem und diskutiert mögliche Lösungswege am Beispiel einer Lambda-Funktion mit Python 3.6 Runtime.
Das Problem
AWS Lambda unterstützt mehrere Sprachen durch die Verwendung von Laufzeiten. Man wählt eine Laufzeit, wenn eine Funktion angelegt wird und kann diese bei Bedarf ändern. Die zugrunde liegende Ausführungsumgebung bietet zusätzliche Bibliotheken und Umgebungsvariablen, auf die der Funktionscode zugreifen kann.
Wählt man bspw. Python3.6 als Runtime, wird das AMI “Amazon Linux“ mit Linux Kernel “4.14.171-105.231.amzn1.x86_64” verwendet (siehe auch https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html). Sollte man im Code jedoch Bibliotheken benötigen, die nicht im AMI mitgeliefert werden, müssen diese der Lambda-Funktion zur Verfügung gestellt werden, da sich die Bibliotheken nicht wie gewohnt importieren lassen.
Falls die bekannte pandas-Bibliothek genutzt werden soll, wird die Lambda-Funktion schon während des Imports von pandas auf Probleme stoßen und folgende Fehlermeldung ausgeben:
Unable to import module 'lambda_function': No module named 'pandas'Die Lösung
Glücklicherweise hat AWS dieses Problem bedacht und mehrere mögliche Lösungswege bereitgestellt. Bevor mögliche Lösungswege diskutiert werden ein wichtiger Hinweis, der für alle Lösungen gilt: Viele Bibliotheken sind für spezifische Versionen der Runtime veröffentlicht. Daher ist es wichtig, die benötigten Bibliotheken hinsichtlich der Runtimeversion zu checken (Bspw über https://pypi.org/). Am Beispiel von pandas ergibt sich folgendes Bild (Quelle: https://pypi.org/project/pandas/#files, 01.07.2020):
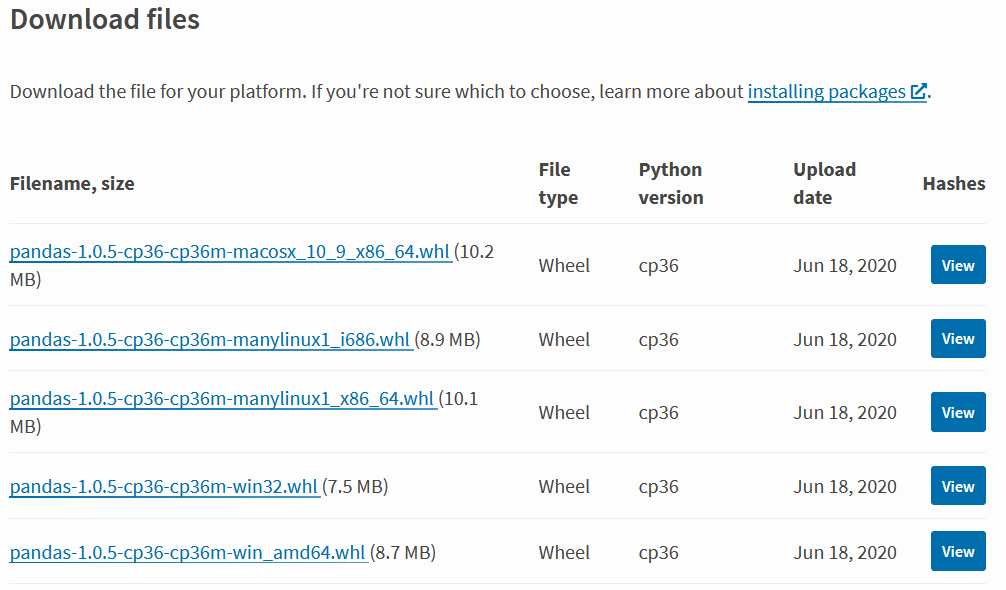
Hier sieht man, dass die Pythonversion für pandas zur Zeit bei Python 3.6 liegt, weshalb die Runtime der Lambda-Funktion entsprechend eingestellt werden sollte:
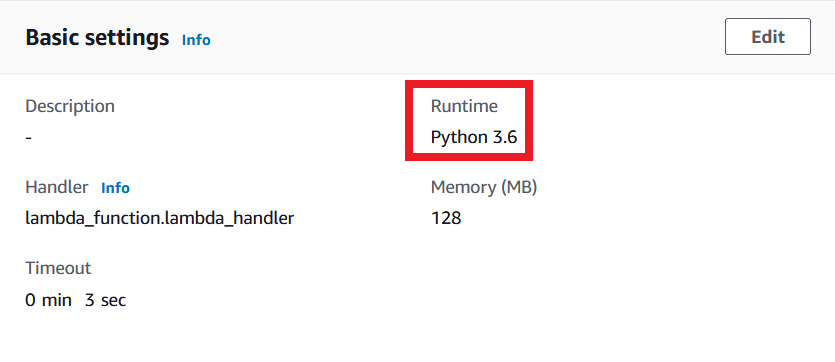
Wie also stellt man Lambda nun die benötigten Bibliotheken zu Verfügung? Hier gibt es mehrere Lösungswege:
- Manuelles installieren von .whl- oder tar.gz-files
- Installieren mit “target”-Option von pip
- Nutzung von AWS Lambda Layers
Um das richtige Paket auszuwählen, muss man wissen, dass Amazon AMIs einen *.x86_64”-Kernel verwenden. Daher sind Pakete auszuwählen, wekche für diesen Kernel ausgelegt sind:
*-manylinux1_x86_64.whlManuelles installieren von .whl- oder tar.gz-files
Hierbei werden die entsprechenden Bibliotheken explizit zum Verzeichnis hinzugefügt, in welchem der Funktionscode liegt. Das entsprechende Paket (in diesem Beispiel pandas) wird als .whl oder .tar.gz Datei heruntergeladen und in das Verzeichnis der importierenden Lambda-Funktion verschoben. Für Pandas muss folgendes Paket ausgewählt (vgl. Bild 2),
pandas-1.0.5-cp36-cp36m-manylinux1_x86_64.whlin den entsprechenden Ordner verschoben und mit
unzip pandas-1.0.5-cp36-cp36m-manylinux1_x86_64.whlentpackt werden (bspw mit der Cmder-Konsole, die Linuxbefehle unter Windows zur Verfügung stellt: https://cmder.net/). Im Fall von Pandas müssen zwei weitere Pakete installiert werden:
- numpy
- pytz
Im Anschluss sollte man nicht benötigte Artefakte entfernen:
rm -r *.whl *.dist-info __pycache__Das Endergebnis sollte wie folgt aussehen:

Abschließend wählt man alle Dateien, einschließlich Funktionscode, aus und fügt diese zu einer .zip-Datei hinzu. Diese kann nun in Lambda anstelle des Funktionscode genutzt werden:

Cloud 9 (Entwicklungseditor von Lambda) kann Code nur bis zu einer Größe von 3MB darstellen, weshalb die Bearbeitungsmöglichkeit im Browser meist entfällt.
Installieren mit “target”-Option von pip
Anstatt alle Pakete manuell zu installieren, kann man einen Paketmanager wie “pip” nutzen. Mithilfe des “target”-flags kann bestimmt werden, in welchen Ordner das Package installiert werden soll:
pip install --target ./<<dir>> pandasZusätzlich kann das “–no-deps“ flag verwendet werden. Hierdurch wird nur die Bibliothek und nicht dessen Dependencies heruntergeladen. Somit bläht sich die Größe des Deployment packages nicht unnötig auf.
Anschließen erstellt man wie bei Lösungsweg 1 ein .zip-file und lädt dies bei AWS Lambda hoch. Siehe auch: https://docs.aws.amazon.com/lambda/latest/dg/python-package.html#python-package-dependencies
Diese Möglichkeit spart im Vergleich zu 1 Zeit, hat jedoch zur Folge, dass das Deployment Package unnötig aufgebläht werden kann.
Lambda Layers
Die “AWS-nativste” Lösung ist die Nutzung von sog. Lambda Layers. Diese muss man einmalig konfigurieren und kann sich im Anschluss auf die Entwicklung des Codes konzentrieren und umgeht das wiederholte hochladen von zip-Dateien, falls Codeänderungen einen neuen Upload nötig machen.
Zur Vorbereitung müssen die entsprechenden Bibliotheken mit einem der beiden vorgestellten Vorgehen heruntergeladen werden und Runtime-spezifisch strukturiert und in einer .zip-Datei gepackt werden. Für Python ergibt sich folgende Struktur:
lambda_layer_package.zip
├───python
├───numpy
│ ├───[subfolders...]
├───pandas
│ ├───[subfolders...]
└───[additional package folders...]Andere Programmiersprachen benötigen ähnliche Ordnerstrukturen, siehe dazu auch https://docs.aws.amazon.com/lambda/latest/dg/configuration-layers.html#configuration-layers-path.
Um einen Layer zu nutzen, erstellt man diesen im Hauptmenü von Lamba, indem man die Option “Layers” (siehe Bild) auswählt und dann über den Button “Create Layer” einen Layer anlegt.
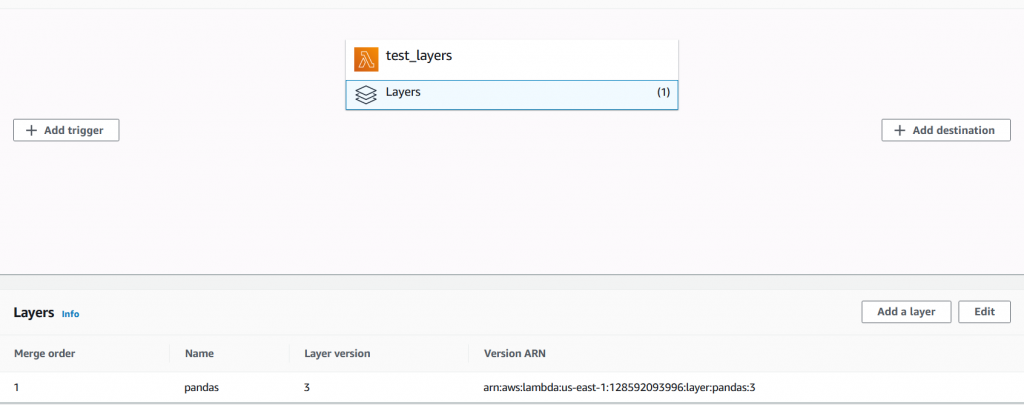
Im Create-Dialog wählt man Name, Dependency-Package und eine Runtime entsprechend der Lambda-Funktion aus. Im Anschluss fügt man im Reiter “Design” der Lambda-Funktion den entsprechenden Layer hinzu:
Die Verwendung von Layern bietet Entwicklern einige Vorteile. In erster Linie können sie sich auf die Logik der Anwendung konzentrieren, anstatt sich um das zusätzliche Bibliotheken zu kümmern. Sobald ein Layer erstellt und konfiguriert ist, wird die Bereitstellung von neuem Code bequem, da die erneute Bereitstellung von Bibliotheken nun überflüssig ist.
Ein weiterer Vorteil ist die Tatsache, dass Schichten in anderen Funktionen wiederverwendet und sogar versioniert werden können, was Zeit und damit Kosten spart.
Falls Lambda Layers verwendet werden sollen, darf die Gesamtgröße des Deployment-Pakets 250MB (entpackt) nicht überschreiten!
Mehr Informationen zu Lambda Layers: https://docs.aws.amazon.com/lambda/latest/dg/configuration-layers.html