
Deep Dive Into AWS Lambda – Part I
In this mini-series, we are going to provide a deeper look into AWS Lambda. The first part recaps the two-sided concept, what execution models you have to know, and how a lambda functions lifecycle is structured. In another article, we discussed the basics of AWS Lambda: What it is, when and why it should be used and how possible applications could look like. Find the article here: Introduction into Lambda
A two-sided concept
As you recall, AWS Lambda relies on two important components: The function policy and the IAM Execution role. The function policy defines, which resources are allowed to invoke a Lambda function. Possible event triggers are data stores, endpoints, repositories, or message services. Function policies are automatically added when the first is trigger added to a function. Additionally, setting up a trigger adds the role „Lambda:InvokeFunction“ to the event source. But how does a policy look? A functions specific permissions can be found in the main menu of the lambda function in the „Permissions“ tab.
Code snippet 1 shows a simple function policy for an S3 Bucket to invoke Lambda. The principle key refers to the service that the trigger, in this case, the bucket, belongs to. Furthermore, the function is referenced by its amazon resource number (arn) and so is the specific bucket. One important note: The resource must be located in the same region as the function. Even though S3 is a global service this is required. Furthermore, when adding new triggers you need to make sure, that the execution role already allows for basic actions on the new trigger.
{
"Version": "2012-10-17",
"Id": "default",
"Statement": [
{
"Sid": "lambda-d33de16c-9e51-4f35-b208-b09ad8d0430a",
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:eu-central-1:***********:function:testFunction",
"Condition": {
"StringEquals": {
"AWS:SourceAccount": "*************"
},
"ArnLike": {
"AWS:SourceArn": "arn:aws:s3:::lambda-test-bucket-f**********"
}
}
}
]
}The IAM execution role defines, what the lambda function is allowed to do once it is invoked. The policy must be selected or created when defining a new AWS Lambda function. Either way, the following three permission must be granted tot he function:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvens
These three permissions allow Lambda to create a log group in CloudWatch and send information to CloudWatch. This makes sure that the user can review current statistics about the usage, error counts, concurrent invocations, and other metrics.
Execution Models
Execution models are another important aspect of Lambda functions and you need to consider them when you design your application’s architecture. You have to consider synchronous/asynchronous triggers and polling. Lets first discuss synchronous and asynchronous triggers.
Synchronous triggers require immediate action by the lambda function the invoking process is waiting for the function to finish. This is important since a long-running lambda function could potentially block your application. Another important detail is the fact, that synchronous triggers do not provide automatic retries. Thus, error handling must be considered when writing the application code. An example of a synchronous trigger ist he API Gateway which invokes a function and then waits for the function to finish before responding to a user’s API call.
Asynchronous triggers, on the other hand, allow the trigger source to just invoke the function without waiting for a confirmation. When triggered asynchronously, the lambda function automatically tries to execute its code three times. Additionally, you can configure a Dead Letter Queue (DLQ) where unsuccessful runs are saved for further analysis. After three failed runs, AWS Lambda automatically drops the respective data to the DLQ. The following list includes some possible asynchronous trigger sources:
- Amazon Simple Storage Service (Amazon S3)
- Amazon Simple Notification Service (Amazon SNS)
- Amazon Simple Email Service (Amazon SES)
- Amazon CloudWatch Logs
- Amazon CloudWatch Events
- AWS CodeCommit
- AWS Config
Some closing notes on the invocation type: When invoking a Lambda function programmatically, you must specify the invocation type. When using AWS services are the source, the invocation type is predetermined.
AWS Lambda polling can be an interesting alternative to the discussed execution models. Lambda can be used to poll a message queue or stream and extract a message object from the source. Polling is interesting because, as of now, polling itself does not cost as long as the function is not triggered by an extracted message object. Also important to know when you consider using polling: Error handling depends on the source. When polling from a stream a failure blocks the application since usually the order of streamed events matters. The function is blocked as long as the event is not expired. Processing errors on events pulled from a queue, on the other hand, are either send to the DLQ or are discarded. Therefore, make sure to take a look at the documentation when planing your architecture!
The lifecycle of a Lambda function
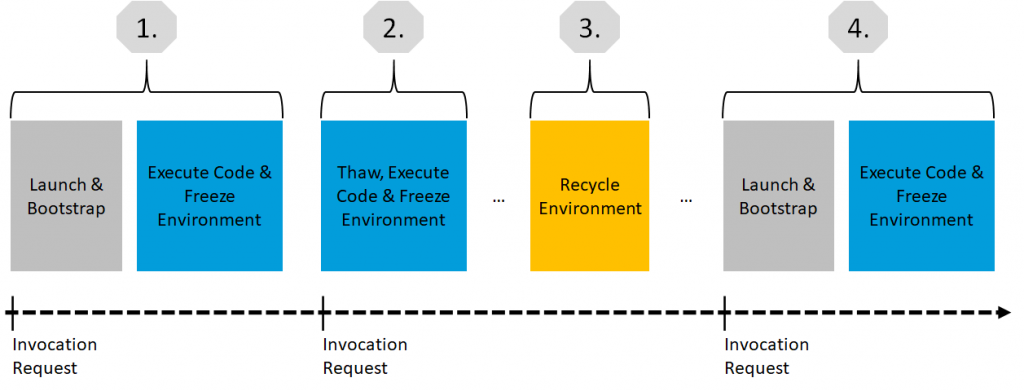
What happens under the hood, when an AWS Lambda function is invoked? To understand a function’s lifecycle when invocated is important if you want to fully understand how Amazon designed the pricing for AWS Lambda. The following steps are taken when a function is triggered:
- Upon invocation, an execution environment is launched and bootstrapped. Once the environment is bootstrapped, your function code executes. Then, Lambda freezes the execution environment, expecting additional invocations.
- If another invocation request for the function is made while the environment is in this state, that request goes through a so-called „warm start“. On a warm start, the available frozen container is thawed and immediately begins code execution without going through the bootstrap process.
- This cycle continues as long as requests continue to come in consistently. But if the environment becomes idle for too long, the execution environment is recycled.
- A subsequent request starts the lifecycle over, requiring the environment to be launched and bootstrapped. This is called a „cold start“.
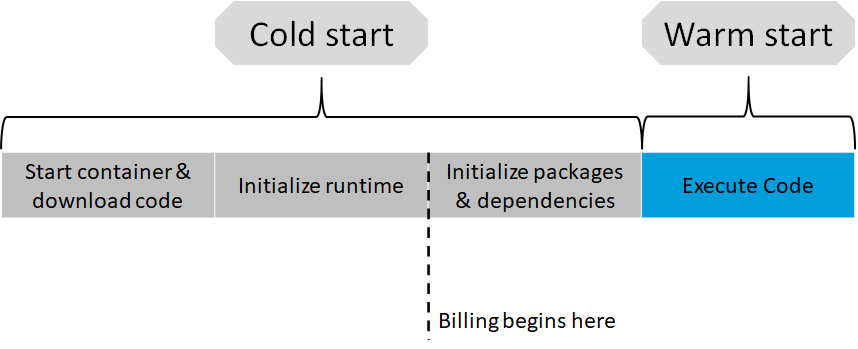
How does this relate to pricing? Well, AWS starts to count execution time when packages and dependencies are initialized. Thus from that point on you can optimize your environment to be as lean as possible by including only dependencies and packages that are necessary to execute the code.
This was the first part of the mini-series on AWS Lambda. In the second part, we take a look at best practices when designing and writing code for Lambda. Additionally, we look at concurrency and limits of AWS Lambda.
More information on the topic: